Nanopore direct RNA sequencing: fundamental principles and developmental trajectory
DRS employs nanopore sequencing technology to perform single-molecule sequencing of native RNA molecules [34]. Unlike traditional approaches, this method does not require RT of RNA into cDNA, thereby avoiding biases that may be introduced during RT and PCR amplification [35]. The underlying principle is based on the translocation of single-stranded RNA through a biological nanopore embedded in a membrane under an applied electric field. Because RNA molecules carry a negative charge, a motor protein drives the RNA into the nanopore at a controlled speed under voltage. Typically, the motor protein attaches to the poly(A) tail at the 3′ end of mRNA via an adapter sequence, enabling the RNA to translocate through the pore in a 3′-to-5′ direction. When a short segment of the RNA strand (approximately 5 nt) occupies the narrow constriction of the nanopore, it impedes ionic current flow and produces characteristic changes in the electrical signal (Figure 2A) [36], [37]. Different nucleotide sequence combinations generate current changes of varying magnitudes, allowing the electrical signals to be regarded as “fingerprints” of the corresponding k-mer sequences [9], [35], [38], [39]. The sequencing device records these current signals in real time and interprets them into nucleotide sequences using deep learning algorithms, a process known as basecalling [38], [40]. Recent high-accuracy models developed by ONT leverage neural networks to interpret current waveforms, enabling real-time and increasingly precise RNA sequencing [41], [42].
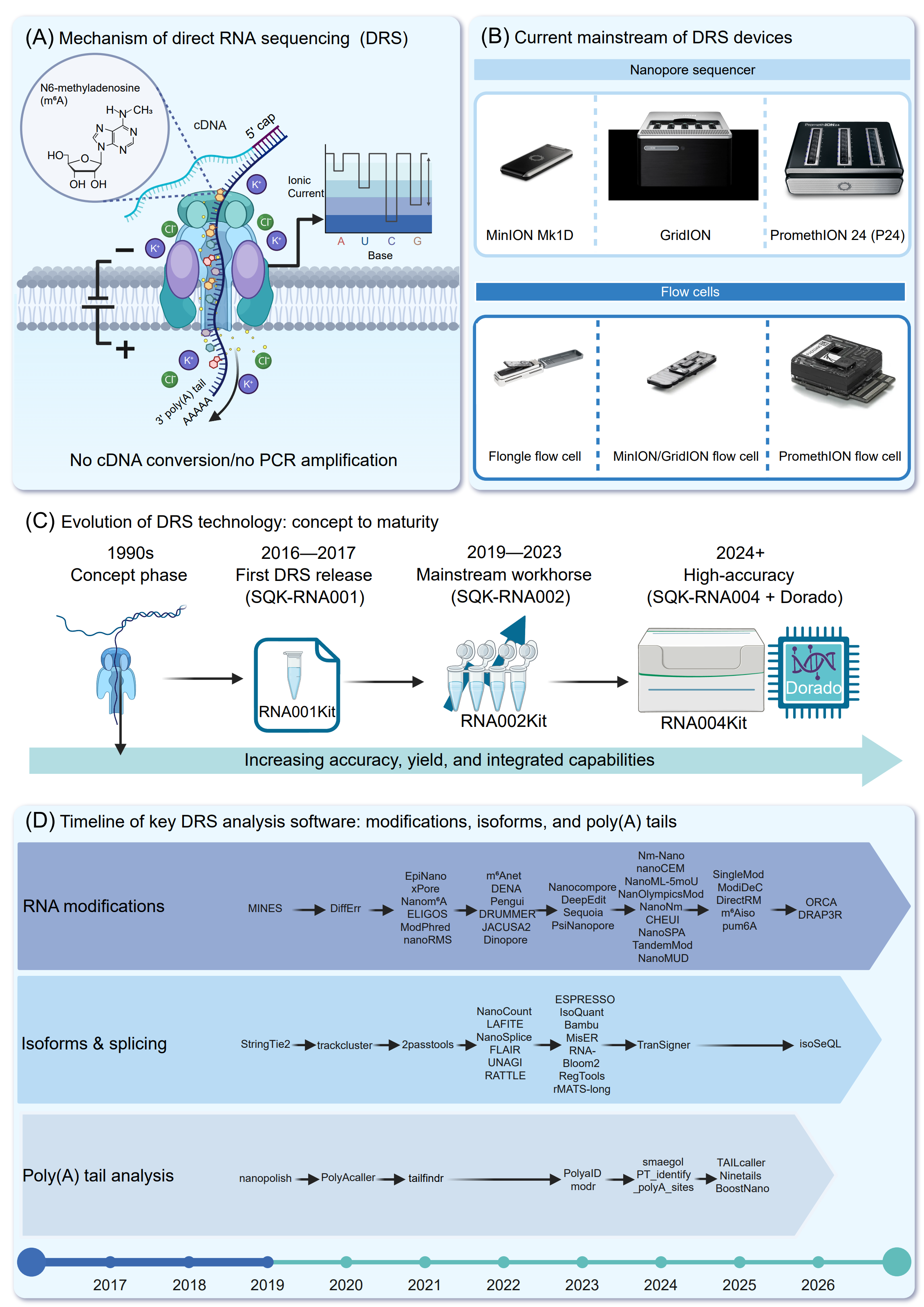
Figure 2. Overview of Oxford nanopore direct RNA sequencing (DRS) technology, platforms, and software. (A) Schematic of the principle of DRS. Native poly(A)+RNA molecules are sequenced directly through a biological nanopore without cDNA synthesis or PCR amplification. As RNA passes through the pore under an applied voltage, nucleotide-specific disruptions in ionic current enable base calling and direct detection of RNA modifications such as N6-methyladenosine (m6A). (B) Current mainstream nanopore platforms and consumables supporting DRS, including MinION Mk1D, GridION, and PromethION instruments, together with corresponding flow cells (Flongle, MinION/GridION, and PromethION). (C) Evolution of DRS technology from early conceptual foundations to mature, high-accuracy workflows. Key milestones include the first commercial DRS kit (SQK RNA001; 2016-2017), establishment of RNA002 as a mainstream workhorse (2019-2023), and recent advances integrating RNA004 chemistry with Dorado basecalling (2024+), resulting in increased accuracy, throughput, and functionality. (D) Timeline of major computational tools developed for DRS data analysis, highlighting methods for RNA modification detection, isoform and splicing analysis, and poly(A) tail length estimation. The progression illustrates rapid expansion and increasing sophistication of the DRS bioinformatics ecosystem from 2017 to the present.
Although DRS has only recently matured into a robust platform, its conceptual foundation dates back several decades. In 1989, the American scientist David Deamer first proposed the idea of driving single-stranded DNA or RNA molecules through nanoscale pores to read their sequence information [43]. In the mid-1990s, key experimental advances were achieved. Kasianowicz and colleagues observed ionic current blockade events when single-stranded nucleic acids passed through an α-hemolysin biological pore which laid the foundation for subsequent single-molecule sequencing [43]. By the late 1990s, “nanopore sequencing” gradually emerged and was adopted as a formal term and technological approach. During the same period, Hagan Bayley and colleagues conducted related technical research. They developed a method to detect molecular characteristics by measuring stochastic fluctuations in nanopore ionic currents, known as stochastic sensing [44], [45]. They also recognized that this approach could be applied to DNA sequencing. The Staphylococcus aureus membrane channel protein α-hemolysin has an inner diameter of approximately 1.4−2.4 nm [43], [46]. It was the first nanopore proven to allow the passage of RNA and DNA homopolymers while producing identifiable ionic current blockade signals [43], [47], [48].
The founding of ONT by Hagan Bayley and Gordon Sanghera in 2005 greatly accelerated the transition of nanopore sequencing from concept to application [43]. In the decade following ONT’s establishment, the company’s research team continuously worked on optimizing biological nanopore materials and sequencing enzymes [39]. For example, they engineered the protein CsgG to develop the R9 series of nanopores and upgraded sequencing enzymes, gradually enabling high-throughput DNA sequencing [49], [50].
This innovation broke the dependence of traditional sequencing on laboratory settings and enabled long-read DNA sequencing to be performed outside conventional laboratories [43]. In December of 2016, ONT provided the first DRS reagent kits (code: SQK-RNA001) to a small group of researchers for testing (https://nanoporetech.com/news/news-direct-rna-sequencing-minion-new-paper-preprint). In April 2017, ONT further expanded access by officially making RNA direct sequencing kits available to its user community (https://nanoporetech.com/news/news-direct-rna-sequencing-nanopore-opens-more-users), and preliminary experimental results of direct RNA sequencing were presented at the London Calling conference in May of the same year (https://nanoporetech.com/news/news-london-calling-2017-day-2-updates). In 2018, the ONT research team reported the first comprehensive DRS study in Nature Methods [9], demonstrating full-length sequencing of yeast mRNA and the feasibility of detecting RNA modifications directly from electrical signals [9].
Since the introduction of the first-generation SQK-RNA001 kit, DRS has undergone rapid technological improvements (Figure 2B) [51]. Early applications using this kit demonstrated its potential for complex transcriptome analysis, including simultaneous assessment of transcript diversity, poly(A) tail length, and RNA modifications in human samples [35]. In 2020, a plant transcriptome study showed that DRS could reveal splicing isoforms, alternative polyadenylation (APA) site selection, and m6A modification patterns in Arabidopsis thaliana mRNA [52]. Building upon the SQK-RNA001 kit, ONT released an improved RNA sequencing kit, SQK-RNA002, in 2019. This updated version substantially improved both data yield and stability, and became the mainstream DRS solution between 2019 and 2023 [53]. More recently, the SQK-RNA004 chemistry, introduced in 2023 and fully commercialized in 2024, further enhanced performance through redesigned nanopores and optimized motor proteins (Figure 2C). While maintaining similar error profiles, RNA004 substantially reduces overall error rates, achieving up to ~98% accuracy (F1-score: 96–99%), compared with ~90–94% for SQK-RNA002, while also increasing read output [53], [54], [55].
A key strength of DRS lies in its ability to generate multidimensional data beyond sequence information alone. By directly sequencing native RNA molecules, DRS preserves chemical modifications such as m6A, Ψ, m5C, and inosine, which subtly alter ionic current signals and can be detected computationally (Figure 2D) [34], [56], [57], [58]. The latest DRS basecalling algorithms incorporate dedicated electrical signal models that are trained on modification-aware data and can be used to infer multiple RNA modification types and their positions from nanopore current signals [59]. Because the 3′ poly(A) tail of mRNA consists of repeated identical nucleotides, its corresponding segment produces a low-variance signal in the sequencing current. By analyzing this signal and correcting for the translocation speed of the molecule through the nanopore, the poly(A) tail length of each transcript can be estimated [35]. Dedicated software tools, such as nanopolish-polya, have been developed for this purpose. These tools segment the raw electrical signal into poly(A) regions and measure their dwell time. The number of adenosines in the tail can then be inferred from these measurements [35], [52]. In summary, nanopore DRS enables long-read, amplification-free RNA sequencing through the interpretation of electrical current signals. This technology not only provides sequence information but also simultaneously captures multiple layers of transcriptomic features, including splicing variation, transcript structure, base modifications, and poly(A) tail length [52], [60].
ONT also released a new generation of open-source basecalling software, Dorado (https://nanoporetech.com/platform/accuracy), which employs improved deep-learning basecalling models that enhance accuracy and speed. Since its release in 2023, Dorado has undergone rapid development, transitioning from version 0.x to 1.x. The 1.1 and 1.2 updates in 2024 introduced optimized High Accuracy (HAC) and Super Accurate (SUP) models, while the 1.3 series in 2025 added support for 2’-O-methylation (Nm). The latest model (1.4.0) optimized for RNA004 signal profiles, achieved substantial improvements in read accuracy. For example, SQK-RNA004 data base-called with Dorado (v0.8.0) achieved a median alignment identity of 98.67% (reads ≥ 200 aligned bases) whereas SQK-RNA002 reads base-called with Guppy (v6.3.8) reached 90.65%, highlighting the higher single-read accuracy obtained when using SQK-RNA004 together with Dorado [53]. Deep learning models of Dorado also support de novo detection of multiple RNA modifications, such as m6A, m5C, inosine, Ψ, and Nm, within a single DRS run. In validation experiments with SQK-RNA004 data, Dorado’s Ψ and m6A models achieved high performance, with accuracies and F1-scores generally in the mid-90% range or higher [53], [61]. Collectively, these advances mark the transition of nanopore DRS into a relatively high-accuracy era, enabling more reliable characterization of transcript sequences and epitranscriptomic features [62]. From proof-of-concept to the implementation of SQK-RNA001 and SQK-RNA002, and now to the maturation of SQK-RNA004 combined with Dorado, each technological iteration represents a step toward higher accuracy and broader application of DRS [53]. These advances provide valuable tools for comprehensive analysis of transcriptional regulation. With continued optimization of algorithms and sequencing chemistries, DRS is expected to play an increasingly important role in transcriptome research, RNA modification mapping, and RNA-based therapeutic development [53], [63].